How to Allow Customers Compiler Access Using WHM
Here, in this article, we will learn how to allow the customers Compiler Access using…

Until now it might be quite clear what is OpenStack. You simply say that OpenStack is a stack of open-source software that used by service providers to set up and run their cloud computing and storage infrastructure.
In the previous post, we engulfed the knowledge of OpenStack and its five key components out of eleven. In this post, we will continue with the next six components that contribute to OpenStack.
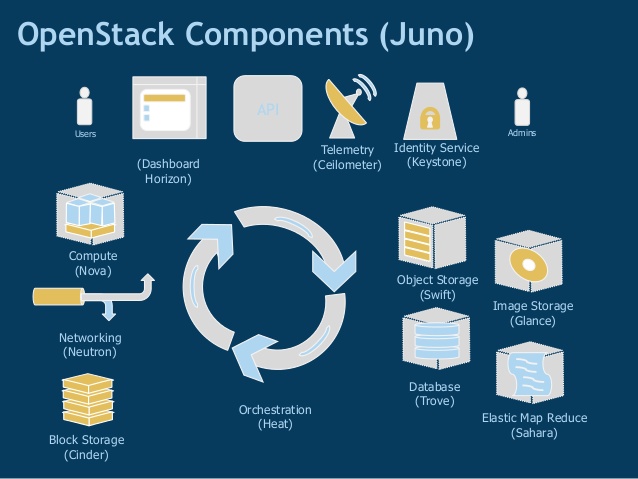
Dashboard (Horizon) –
It offers a web-based portal for interacting with all the underlying OpenStack services like NOVA, Neutron, etc. That means it is the primary graphic user interface for using OpenStack clouds. With this tool users and administrators can provide and automate services.
Also, developers are able to access the OpenStack components individually through an application programming interface (API).
OpenStack Networking (Neutron) –
It is an API-driven system for managing networks that plugged as well as scaled. After network customization, it allows to spin up and down several variant network types (like flat networks, VLANs or virtual private networks) on-demand.
Neutron permits dedicated or floating IP addresses. In addition, it supportive of OpenFlow software-defined networking protocol and services including load balancing, intrusion detection, and firewalls with the help of plugins.
OpenStack Telemetry Service (Ceilometer) –
Monitoring the usage of cloud services and deciding the billing accordingly is the major role of Ceilometer. Additionally, it uses for deciding the scalability and obtaining the usage stats.
Orchestration Heat –
An orchestration engine that enables developers in automating the deployment of infrastructure known as heat. With orchestration heat, developers can store the cloud application requirements in a file defining the resources essential for that application.
This permits for easier onboarding of new instances. Heat also comes with an auto-scaling feature with which additional resources added as required by the services.
Trove –
Designed to run entirely on OpenStack, Trove is a Database-as-Service for OpenStack. It allows users quick and easy utilization of relational or non-relational database features without the stress to handle complex administrative tasks.
The prime objective of the service will be providing resource isolation at high-performance parallel to automating complex administrative tasks including configuration, deployment, monitoring, backups, patching, and restores.
Sahara –
OpenStack Sahara formerly known as Savanash was started by Red Hat, Mirantis, and HortonWorks during the OpenStack Havana summit in Portland. It enables OpenStack software to control Hadoop clusters. It offers the foundation and innovation hub for clear infrastructure resources management.
With the OpenStack cloud operating system, enterprises, and service providers can offer on-demand computing resources by providing and managing large networks of virtual machines.
Focused on delivering flexibility as per your cloud design, it’s capable of integrating with legacy systems and third-party technologies.
Explore more hosting insights, tips and industry updates.
Here, in this article, we will learn how to allow the customers Compiler Access using…
In cPanel Addon Domain is a feature which provides you to add extra domain name…
The internet relies on unique addresses to identify and locate devices. These addresses, like your…